Entendendo externalTrafficPolicy e internalTrafficPolicy no Kubernetes
Você já deve ter visto no manifesto de um Service o campo externalTrafficPolicy ou internalTrafficPolicy. Mas o que exatamente são e para que servem?
Neste post, vamos entender estes dois parâmetros de uma forma visual e qual o seu papel no balanceamento do tráfego.
externalTrafficPolicy
Este campo, que geralmente é visto em Services do tipo LoadBalancer, como os criados por Ingress Controllers como ingress-nginx e Traefik, controla como o tráfego que vem de fora do cluster é distribuído entre os Pods e possui dois valores:
Cluster(Padrão): Tráfego externo é balanceado para todos os Pods em todos os Nodes, independentemente do Node ao qual o tráfego tenha chegado primeiro.Local: Tráfego externo é balanceado apenas para os Pods presentes no mesmo Node onde o tráfego chegou no cluster.
externalTrafficPolicy: Cluster
Como exemplo, observe o vídeo abaixo sobre como funciona o balanceamento de um pacote que chega a um cluster que contém:
- 3 Nodes, VM1, VM2 e VM3 (vamos ignorar o Node VM2, imaginando que ele falhou no health check do load balancer).
- Um Network LB, criado a partir de um Service do tipo
LoadBalancerpresente no cluster (este configurado comexternalTrafficPolicy: Cluster). - 3 Pods, onde um está no Node VM1 e os outros dois no Node VM3.
Jornada de um pacote do cliente até o Pod quando externalTrafficPolicy: Cluster. Fonte.
Colocando em palavras o vídeo acima:
- O pacote chega ao LB, que irá direcioná-lo a um dos Nodes (em verde). Note que o LB neste ponto tem visão apenas dos Nodes, e não sabe nada sobre o estado dos Pods, sua distribuição, o cluster Kubernetes em si, etc. Seu trabalho é puramente o balanceamento das requisições para as máquinas abaixo de si.
- Após ter escolhido o Node (
VM1), o LB realiza o envio do pacote, onde, ao chegar, passa por um conjunto de regras iptables. Estas regras são gerenciadas pelo kube-proxy, que por estar em DaemonSet, possui uma réplica por máquina. Como estamos utilizando o modo Cluster, as regras presentes no iptables irão balancear a requisição entre todos os Pods existentes, independentemente da máquina onde estão. - O
pod2no NodeVM3é escolhido, com o pacote passando pelo processo de NAT, gerando um pulo de rede extra devido ao balanceamento feito entre todos os Pods no passo anterior pelo iptables. - Após o pacote chegar ao seu destino no
pod2, o caminho inverso é feito, com o pacote voltando para o NodeVM1. - Ao chegar no Node
VM1, o NAT é desfeito com a ajuda doconntrack, que mantém uma tabela com as mudanças feitas pelo NAT anteriormente. - Com o NAT desfeito, o pacote volta em direção ao cliente que realizou a requisição, passando pelo LB no processo.
externalTrafficPolicy: Local
Agora, vamos ver como funciona o balanceamento utilizando o externalTrafficPolicy: Local, tendo o seguinte cenário:
- 3 Nodes, VM1, VM2 e VM3 (vamos ignorar o Node VM2, imaginando que ele falhou no health check do load balancer).
- Um Network LB, criado a partir de um Service do tipo
LoadBalancerpresente neste cluster (este configurado comexternalTrafficPolicy: Local). - 3 Pods, onde um está no Node VM1 e os outros dois no Node VM3.
Jornada de um pacote do cliente até o Pod quando externalTrafficPolicy: Local. Fonte.
- O pacote chega ao LB, que irá direcioná-lo a um dos Nodes (em verde). Como neste exemplo
VM2falhou nos health checks do LB, ele não pode ser escolhido. - Node
VM3é escolhido e o pacote chega à máquina, onde passa pelo iptables. Diferentemente do exemplo anterior, por utilizarmos a configuraçãoLocal, o balanceamento do pacote será feito apenas para os dois Pods presentes no NodeVM3(pod2epod3). - Com o
pod2sendo o Pod escolhido, o pacote passa por DNAT, tendo seu destino modificado para opod2. - O Pacote chega ao seu destino e inicia seu caminho de volta, tendo seu NAT desfeito com auxílio do
conntrack. - O Pacote sai do Node
VM3em direção ao cliente, passando pelo LB no processo.
Diferenças entre Cluster e Local
Cluster
- O IP do cliente é perdido.
- O tráfego é balanceado corretamente entre todos os Pods.
- Pode causar um salto adicional de rede durante o percurso (podendo causar aumento na latência).
Local
- O IP do cliente é preservado.
- A depender da localidade e quantidade dos Pods nos Nodes, o tráfego pode ficar desbalanceado entre os Pods.
- Sem salto adicional de rede durante o percurso.
Considerações ao escolher o modo Local
Ao utilizar o modo Local, o tráfego externo que chega a um Node é encaminhado exclusivamente para os Pods hospedados naquele mesmo Node. Como os load balancers externos geralmente distribuem o tráfego de forma igualitária entre os Nodes (e não entre os Pods), existe um risco significativo de distribuição não uniforme do tráfego, a menos que o workload seja um DaemonSet ou utilize regras estritas de podAntiAffinity ou topologySpreadConstraints.
Para os cenários abaixo, a distribuição do tráfego será equilibrada (similar ao modo Cluster):
- Número de Pods muito maior que o de Nodes.
- Como há uma grande quantidade de réplicas, o scheduler do Kubernetes distribuirá os Pods de forma relativamente igual entre os Nodes disponíveis. Mesmo que um Node tenha alguns Pods a mais que outro, o grande volume total de réplicas dilui a diferença, fazendo com que a carga recebida por cada Pod individualmente seja próxima de um equilíbrio aceitável.
- Número de Nodes muito maior que o de Pods.
- Neste cenário, a probabilidade de um mesmo Node hospedar mais de um Pod é mínima. Como cada Node ativo terá apenas um Pod (comportando-se, na prática, como se fosse um DaemonSet naqueles Nodes específicos), o tráfego distribuído entre os Nodes resultará em um tráfego perfeitamente balanceado entre os Pods.
Entretanto, para o cenário onde:
- Número de Pods próximo ou igual ao número de Nodes.
Pode haver um grande desbalanceamento na distribuição do tráfego, visto que o scheduler pode acabar agrupando múltiplos Pods em alguns Nodes e deixando outros Nodes com apenas uma réplica (singletons).

Número de Pods similar ao número de Nodes pode criar um desbalanceamento no tráfego, caso o workload não seja um DaemonSet ou não sejam utilizadas regras de podAntiAffinity ou topologySpreadConstraints. Fonte.
Balanceamento para Nodes sem Pods
Nos exemplos anteriores, foi mencionado que o Node VM2 não seria considerado no exemplo por “ter falhado no health check do load balancer”. Porém, o que isso realmente quer dizer? Imagine o seguinte cenário:
- Service
LoadBalancerconfigurado comoLocal. - Consideramos o Node VM2 como elegível para receber pacotes.
- Um pacote chega ao LB, e este envia para o Node VM2, que não possui nenhum Pod.
- O pacote chega na máquina, mas não existe nenhum Pod presente. Além disso, não é possível enviar o pacote para Pods em outros Nodes pois estamos no modo
Local.
O que acontece então? O pacote é simplesmente jogado fora e o cliente recebe um timeout?
É justamente este o caso que o health check do load balancer ajuda a evitar. Nos Services do tipo LoadBalancer, existe o parâmetro healthCheckNodePort, que define a porta utilizada para os health checks:
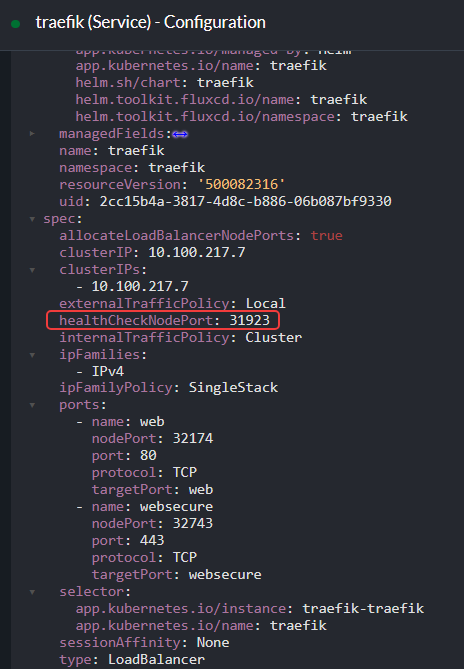
healthCheckNodePort, destacado na imagem, define a porta utilizada pelos health checks feitos pelo load balancer no lado da AWS.
No lado da AWS:
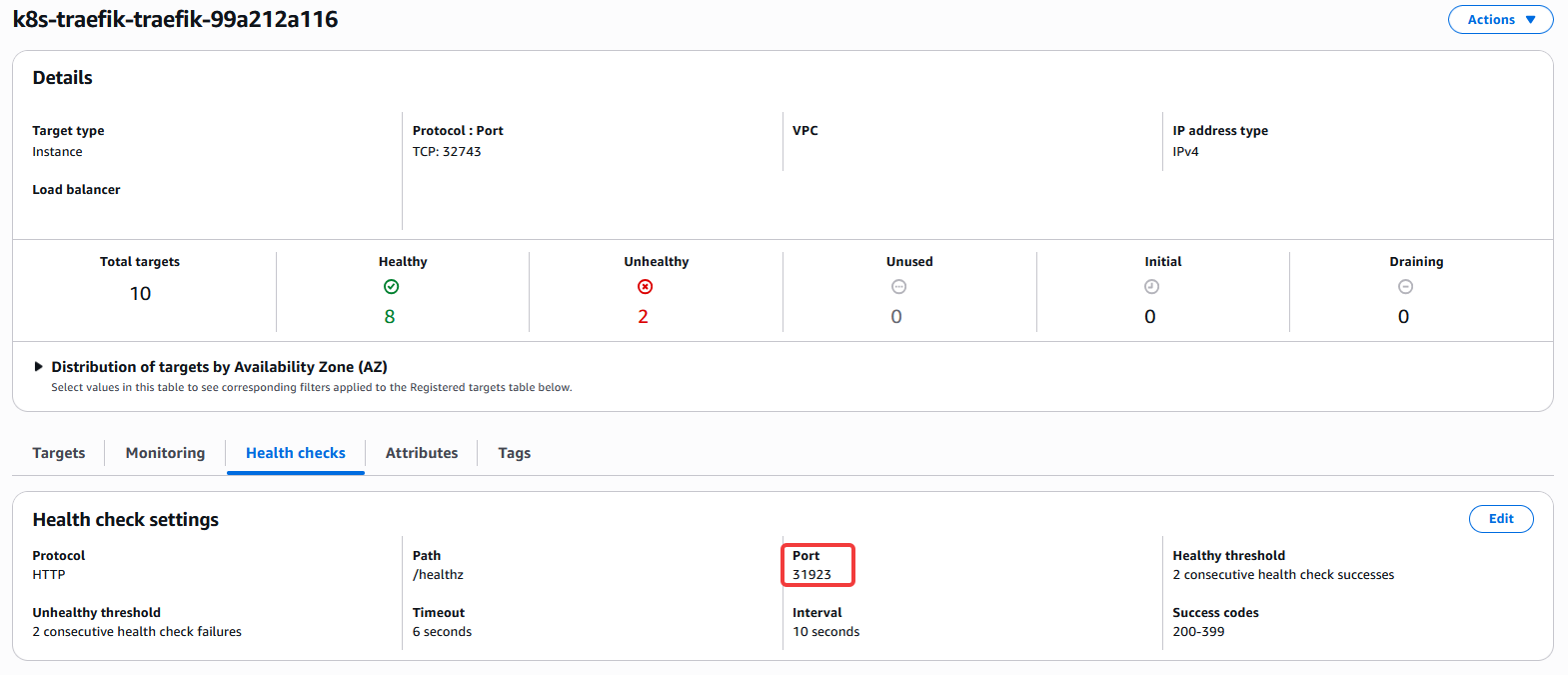
Assim como no manifesto, a porta 31923 também aparece no console da AWS.
O LB envia frequentemente requisições HTTP para todos os Nodes na porta 31923, no path /healthz.
Podemos confirmar que esta porta está de fato exposta rodando o comando ss -tlnup em um dos Nodes do cluster:
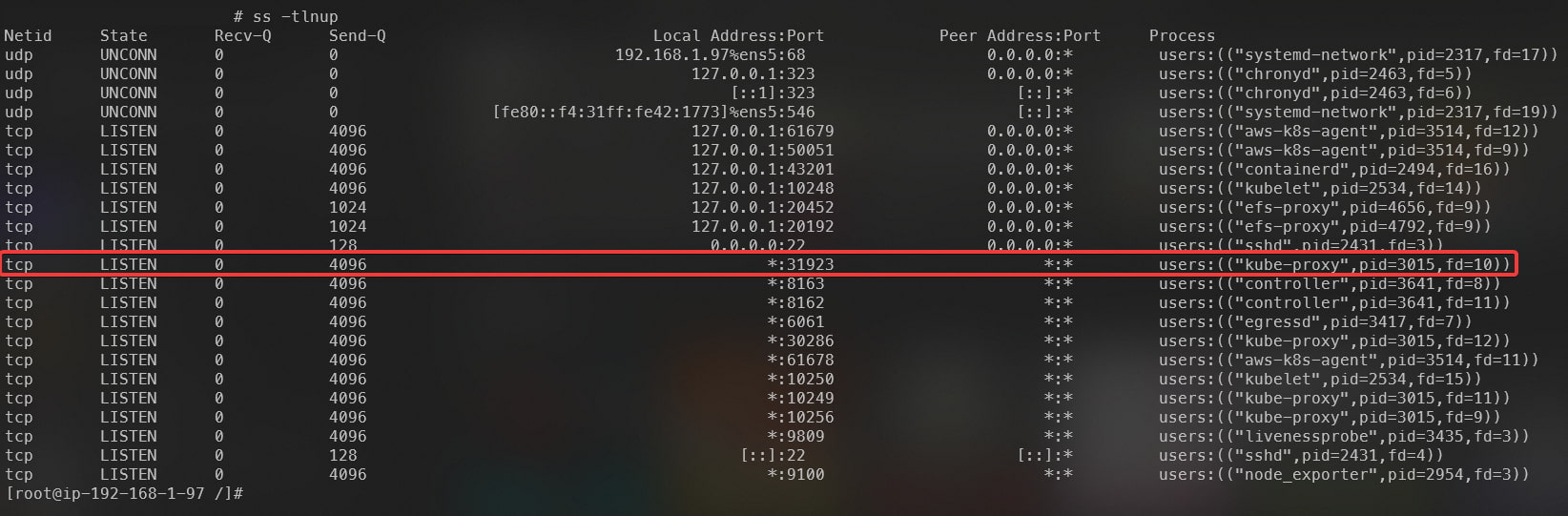
Processo do kube-proxy em destaque, responsável por responder às requisições que chegam ao endpoint localhost:31923/healthz.
O processo do kube-proxy é responsável por responder às requisições que chegam, e como vimos antes no console da AWS, o path utilizado é o /healthz. Podemos então testar este endpoint enviando uma requisição cURL a partir de um dos Nodes para localhost:31923/healthz, obtendo a resposta abaixo:
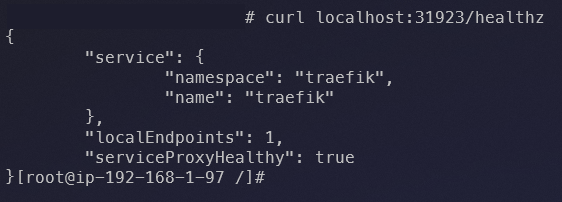
Resposta JSON ao realizar requisição ao endpoint de health check.
A resposta nada mais é que um JSON contendo o nome e namespace do serviço associado ao LB, juntamente com os campos:
localEndpoints→ QuandoexternalTrafficPolicy: Local, retorna a quantidade de Pods relacionados ao serviço associado ao LB (Traefik neste caso), presentes no Node em questão. Como esta instalação do Traefik está em modo DaemonSet, temos um Pod por Node (exceto em dois Nodes que possuem taints neste cluster).serviceProxyHealthy→ Retornatruese o kube-proxy estiver saudável (processo executando e com regras de iptables sincronizadas corretamente com o kernel, garantindo um caminho para chegar ao endpoint do serviço associado ao LB).
Como este Node possui ao menos um Pod do Traefik (localEndpoints >= 1) e o kube-proxy está funcionando corretamente e com as regras iptables sincronizadas, ele é marcado como saudável e fica elegível a receber tráfego externo.
Health checks quando externalTrafficPolicy: Cluster
Ao mudar para o modo Cluster, é possível perceber no manifesto do Service que o campo healthCheckNodePort irá sumir:
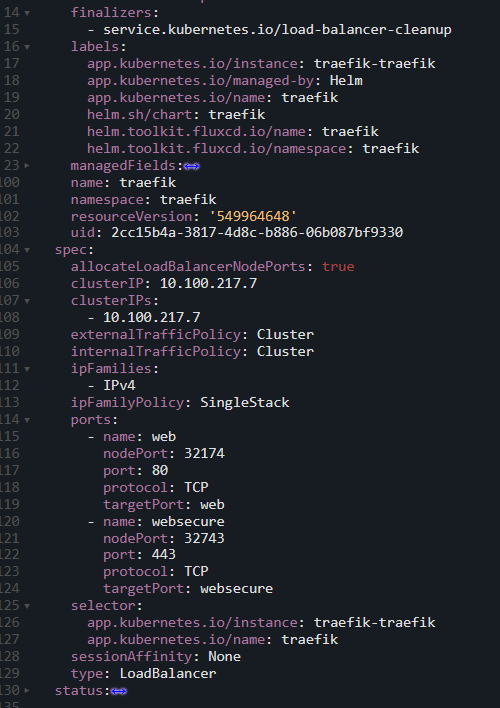
Manifesto de um Service com externalTrafficPolicy: Cluster, mudando a forma como o health check é feito e, como consequência, removendo o campo healthCheckNodePort.
Já no lado da AWS, podemos ver que:
- Protocolo utilizado no health check mudou de HTTP para TCP.
- Path
/healthznão é mais utilizado (visto que o protocolo agora é TCP). - Porta utilizada no health check é a mesma em que o Node aceita requisições de clientes (32174).
- O número de Nodes marcados como saudáveis subiu de 8 para 10, embora ainda existam apenas 8 Pods do Traefik no nosso cluster.
- Outras configurações como intervalo, timeout e thresholds também foram modificados.
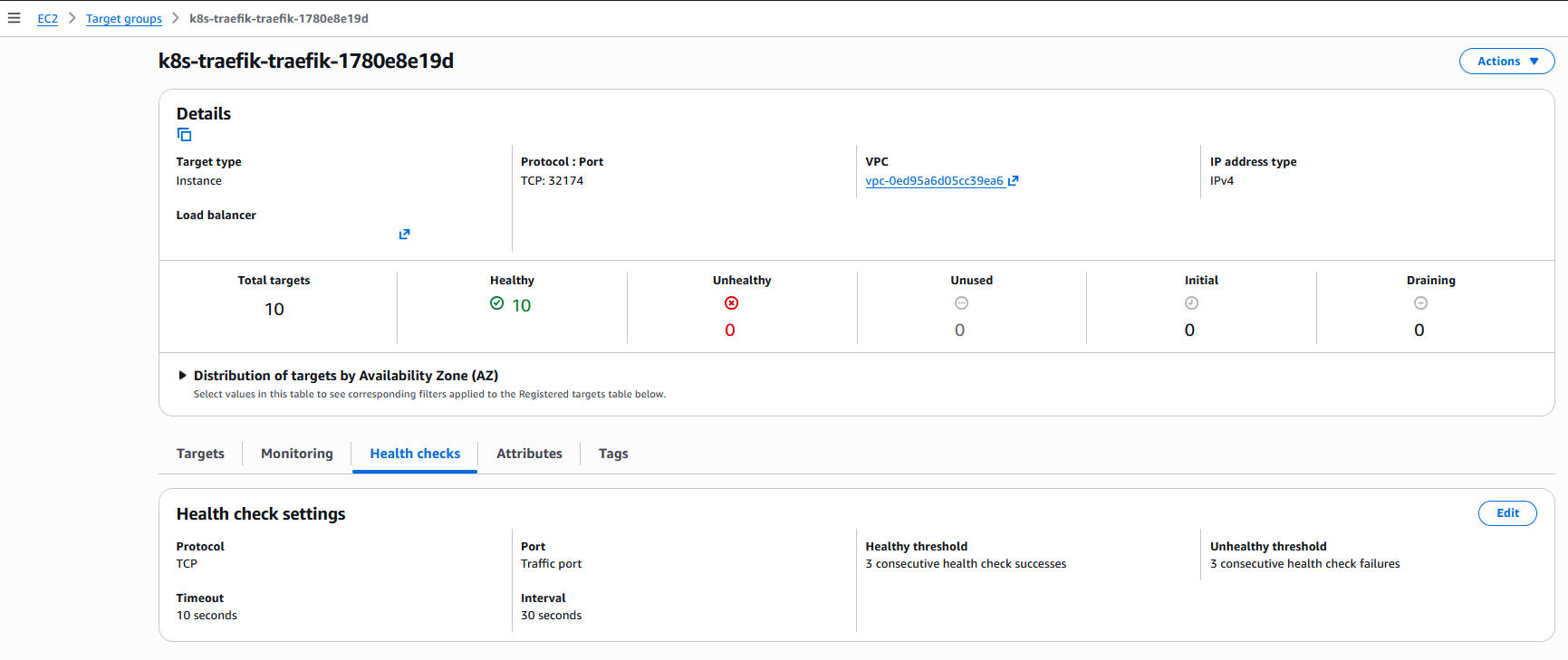
Menu de configurações de health checks de um dos Target Groups do load balancer após a mudança para externalTrafficPolicy: Cluster.
Testando no próprio Node, confirmamos que a porta 31923 antes utilizada não está mais aberta:

Como a forma de realização dos health checks mudou, o processo do kube-proxy, responsável por responder a esse tipo de requisição, deixou de executar.
Entretanto, criou-se uma nova dúvida. Este ambiente possui 10 Nodes, dos quais 2 possuem taints. Como o Traefik, serviço que estamos utilizando de exemplo, está instalado em modo DaemonSet (sem tolerations para estas taints), temos 8 réplicas. Como o número de Nodes considerados saudáveis pelo LB subiu de 8 para 10, se o número de réplicas do Traefik permanece o mesmo?
A resposta está na forma como o health check é feito ao utilizar o modo Cluster. Como o tráfego é balanceado entre todos os Pods, independentemente do Node onde estão, o tráfego pode chegar a um Node que não possui nenhum Pod do Traefik, onde então as regras de iptables irão direcionar este tráfego para um Pod presente em outro Node. Como o health check utiliza a mesma porta por onde o tráfego normal passa, ele segue o mesmo caminho e sempre consegue chegar a um Pod do Traefik, mesmo que o Node onde o tráfego inicialmente chegou não tenha Pods.
internalTrafficPolicy
Esta configuração segue o mesmo princípio lógico do externalTrafficPolicy, mas com um escopo diferente: ela gerencia exclusivamente o roteamento do tráfego interno do cluster (ou seja, requisições originadas por outros Pods e serviços internos).
Outro ponto importante é que o internalTrafficPolicy pode ser utilizado para outros tipos de Service, como ClusterIP, e não apenas para tipos LoadBalancer e NodePort.
A configuração aceita os mesmos dois valores para ditar o comportamento do balanceamento:
Cluster(Padrão): Tráfego interno é balanceado para todos os Pods em todos os Nodes, independentemente de qual Node o tráfego se originou.Local: Tráfego interno é balanceado apenas para os Pods presentes no mesmo Node onde o tráfego se originou.- Se um Pod tentar acessar um Service no modo
Locale não houver nenhuma réplica do Pod de destino rodando no seu próprio Node, o pacote será descartado.
- Se um Pod tentar acessar um Service no modo
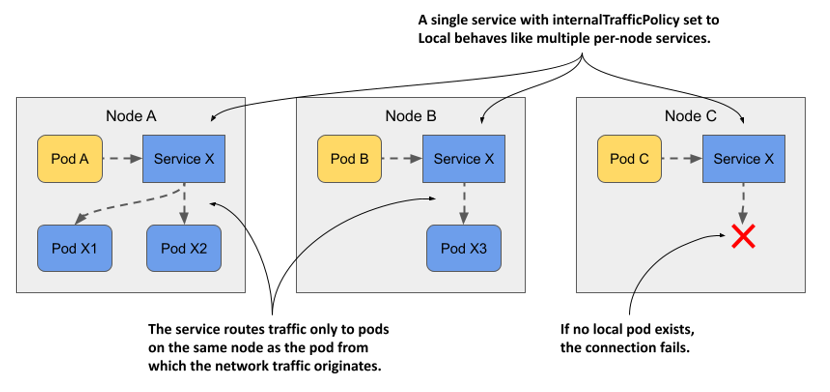
Como funciona a conectividade entre Pods através de um Service com internalTrafficPolicy: Local. Fonte.
Conclusão
Espero que este post tenha ajudado você a entender melhor como o externalTrafficPolicy funciona. Embora possa parecer um conceito difícil, basta uma boa explicação visual para perceber que é algo simples de entender.
Por fim, recomendo assistir à apresentação The ins and outs of networking in Google Container Engine and Kubernetes, que além de conter uma excelente explicação sobre como funciona o networking no Kubernetes, também explica em mais detalhes o externalTrafficPolicy (os vídeos e alguns exemplos utilizados foram obtidos desta apresentação).